INTRODUCTION
Markov decision processes (MDPs), also known as discrete-time controlled Markov processes in the control literature, are a class of discrete-time stochastic control processes with a simple structure that makes them useful in many applications. For example, in reinforcement learning it is assumed that the underlying dynamics can be modeled using MDPs. This blog post isn’t about the applications though, but rather about the more technical existence and uniqueness questions—questions which are often ignored. We will start with carefully defining the Markov decision process and then show a few intuitive results, the last of them being the famous dynamic programming equation.
In an MDP there is an underlying discrete-time Markov process whose trajectory can be influenced by a decision maker by choosing actions from a pre-specified class of admissible actions. The goal is choose actions in such a way so as to optimize a performance criterion. The state of the system at time \(n+1\) then depends, in a Markovian way, on the state of the system and the action chosen at time \(n.\) Depending on how general the state spaces and action space are, this framework can model a wide variety of interesting problems.
Let us discuss a toy problem—inventory control problem—for motivation. You are the manager of a distribution centre which sells the product to shops and buys the product in bulk from a factory. Suppose the maximum capacity of the distribution centre is \(C\) units, and therefore the state space is \(\mathsf S = [0, C],\) i.e., the state of the distribution centre at time \(n\) is a random variable \(X_n\) taking values in \(\mathsf S.\) The action that you can take is order some quantity of product from the factory. The action space \(\mathsf A\) also equals \([0,C]\). At time \(n\) you can observe the state \(X_n\) of the system, and with a policy in mind you order \(A_n\) units from the factory. Of course, \(A_n\) must take values in \([0, C-X_n]\). The demand from the shops is given by the i.i.d. random variables \(\{\xi_n\}_{n \ge 0}\) with a common distribution \(\mu\) on \(\mathsf S.\) It costs \(h\) dollars per unit of product to hold the product, \(b\) dollars per unit of product to buy the product, and earns \(s\) dollars per unit of product to sell the product. Any unmet demand is simply lost revenue. How should you choose a policy \(\pi = \{A_n\}_{n=0}^N\) to maximize the revenue over, say, \(N\) days?
Let us write the model more precisely. Suppose on day \(0\) you start with \(X_0 = x_0\) units of product, which is a constant. Then we have
The revenue on day \(n\) is
The total expected revenue is
Does there exist an admissible policy \(\pi^*\) such that it maximises the total expected revenue? That is,
Is \(\pi^*\) optimal for every starting state \(x_0\)? It will be more convenient to model the transition dynamics of such a model using stochastic kernels, which informally model the transition probabilities of the process. That is, we want to find a stochastic kernel \(\kappa\) from \(\mathsf S \times \mathsf A\) to \(\mathsf S\) which gives the probability of the state at day \(n+1\) being in \(B \subseteq \mathsf S\) given that on day \(n\) the state was \(X_{n}\) and we took action \(A_n\). We can do this as follows
We haven’t been very precise about our formulation. To this end, let us start by defining the objects like stochastic kernels and sets which will define our action and state spaces.
SETTING THE STAGE
I had initially intended for this section to be a small one, but as I wrote I couldn’t help but go on a ramble since it helped me learn. If you are already comfortable with the notions of standard Borel spaces, stochastic kernels (also known as Markov kernels or transition probability kernels) and regular conditional distributions, or if you don’t want to be fully rigorous and are okay with understanding the core ideas without bothering too much with rigour and notation, feel free to skip directly to the section on Markov Decision Process.
Note on notation: I will be using sans serif typestyle for spaces, for example \(\mathsf{S}, \mathsf{T}, \mathsf{A}\) etc., and script typestyle for \(\sigma-\)algebras, for example, \(\mathscr{S}, \mathscr{T}, \mathscr{A}\) etc. In this section I will be fastidiously careful about writing the \(\sigma-\)algebra, but starting from the next section on Markov Decision Processes I often won’t write the \(\sigma-\)algebra explicitly because we will dealing with topological spaces and Borel \(\sigma-\)algebra is to be assumed implicit. But if I am forced to write, then I’ll use the script typestyle of a letter to denote the Borel \(\sigma-\)algebra of the space written in sans serif typestyle of the corresponding letter; for example, \(\mathscr{A}\) for \(\mathsf A.\) We denote the vector space of measurable functions from \((\mathsf X, \mathscr X)\) to \(\mathbb R\) by \(\mathscr X\) — the context will make it clear if we are referring to a function or a set, and what the domain of the function is. We denote the cone (i.e., stable under sums and multiplication by positive constants) of measurable functions from \((\mathsf X, \mathscr X)\) to \([0, +\infty]\) by \(\mathscr X_+.\)
Standard Borel Space
I discussed the notion of standard Borel spaces in the blog post on conditional probability, but since they play an important role in our discussion on Markov decision processes, let me elaborate on them a bit more here. Standard Borel spaces are usually studied under the banner of descriptive set theory and are intimately connected with other descriptive set theoretic concepts like analytic spaces, Lusin spaces and Souslin spaces. We will not focus on this side of the standard Borel spaces though, but rather on some important probabilistic results that can be formulated at this level of generality.
Generally speaking, very few meaningful statements can be made about Markov decision processes when we impose no regularity structure on the spaces involved and let them be any measurable spaces. This is where standard Borel spaces come in — powerful results can be concluded with this structure, and yet they are sufficiently general to be satisfying.
Polish Space
Let us start by recalling Polish spaces.
Examples
Any set with the discrete topology is completely metrizable, and therefore if it is countable it is Polish. So, for example, \(\{0,1\}\), \(\mathbb N\) and \(\Z\), each with the discrete topology, are Polish.
\(\mathbb R^n\) with the usual topology is Polish, for each \(n \in \mathbb N.\)
The topology of any (real or complex) Banach space is completely metrizable, and therefore separable Banach spaces are Polish.
The completion of a separable metric space is Polish.
Any closed subspace of a Polish space is Polish.
The disjoint union of countably many Polish spaces is Polish.
The product of countably many Polish spaces is Polish.
All of these examples follow from elementary properties of metric spaces. So, for example, to show the last example, first show that the product of countably many separable metric spaces is itself separable using the definition of product topology, and then show that the product of countably many complete metric spaces is itself a complete metric space using the idea of the product metric and the definition of Cauchy sequences.
Polish spaces are the probabilist’s favourite spaces to work with since they are simple to deal with and a lot of spaces are Polish, while almost all results that hold in \(\mathbb R\) still hold in a Polish space. For example, if \((\mathsf X,d_{\mathsf X})\) is a compact metric space and \((\mathsf Y, d_{\mathsf Y})\) is Polish, then \(C(\mathsf X,\mathsf Y)\), the set of continuous functions from \(\mathsf X\) to \(\mathsf Y\) with the uniform metric \(d(f,g) = \sup_{x \in \mathsf X} d_{\mathsf Y}(f(x), g(y))\), is Polish.
Standard Borel Space
Recall the notion of isomorphism between algebraic objects or the notion of homeomorphism between topological spaces. Both these notions give a bijective correspondence between two objects that preserves the algebraic or the topological structure. In a similar spirit we have the notion of isomorphism between two measurable spaces.
Let me list some properties about standard Borel spaces without proof–mostly to justify using them as our default spaces.
It is obvious from the definition that two countable metrizable spaces are Borel isomorphic if and only if they have the same cardinality. For the uncountable case, it is not immediately obvious when two spaces are Borel isomorphic. The next proposition is a deep and surprising result.
Observe that \([0,1]\) endowed with its Borel \(\sigma-\)algebra is a Polish space, and therefore every uncountable standard Borel space is isomorphic to \(([0,1], \mathscr{B}([0,1])),\) where the notation \(\mathscr B(\mathsf T)\) denotes the Borel \(\sigma-\)algebra of a topological space \(\mathsf T.\) This observation will prove to be very helpful in proving existence result for regular conditional distributions, in proving the disintegration theorem etc.
This, in particular, implies that if both \((\mathsf S, \mathscr S_1)\) and \((\mathsf S, \mathscr S_2)\) are standard Borel spaces, then \(\mathscr S_1 = \mathscr S_2.\) Now recall that the Borel \(\sigma-\)algebra on \([0,1]\) is a strict subset of the Lebesgue \(\sigma-\)algebra on it. This gives us a simple example of a measurable space which is not a standard Borel space.
A very useful result that further justifies the case for using standard Borel spaces is the following: Let \((\mathsf S, \mathscr S)\) be a standard Borel space and let \(\mathcal{P}(\mathsf S)\) denote the collection of all probability measures on \((\mathsf S, \mathscr S).\) Endow \(\mathcal{P}(\mathsf S)\) with the topology of weak convergence, i.e., the topology generated by the evaluation maps \(\mathcal{P}(\mathsf S) \ni\mu \mapsto \mu(S) \in [0,1]\), where \(S\) varies over \(\mathscr S\) (or equivalently, by the maps \(\mu \mapsto \int f \, \mathrm{d}\mu\), where \(f\) varies over \(C_b(\mathsf S)\)). Then \(\mathcal{P}(\mathsf S)\) equipped with its Borel \(\sigma-\)algebra is a standard Borel space. This fact becomes useful when dealing with partially observable MDPs. Here a standard approach is to transform them into an equivalent “completely observable” MDP (the one in Definition 14 ahead) with a larger state space, a space of probability measures.
A cool fact, which has no bearing on our discussion ahead, is the following.
Stochastic Kernels
Suppose that a particle is moving randomly in a state space given by a measurable space \((\mathsf S, \mathscr{S})\). We would like to be able to know the probability, denoted with say \(\kappa(x, B)\), of the particle finding itself in a set \(B \in \mathscr{S}\) after a unit of time given that it started at state \(x \in \mathsf S.\) Stochastic kernels model this notion of transition probabilities in a natural manner and we will rely heavily on them in our discussion.
Definition 4 (Stochastic kernel): Let \((\mathsf S, \mathscr{S})\) and \((\mathsf T, \mathscr{T})\) be two measurable spaces. A map
\(x \mapsto \kappa(x, B)\) is \(\mathscr{S}-\)measurable for each \(B \in \mathscr{T}\), and
\(B \mapsto \kappa(x,B)\) is a probability measure on \((\mathsf T, \mathscr{T})\) for each \(x \in \mathsf S.\)
We often denote \(\kappa(x, B)\) with \(\kappa_x(B)\) and the mapping \(x \mapsto \kappa(x, B)\) with \(\kappa(B).\) If \((\mathsf T, \mathscr{T}) = (\mathsf S, \mathscr{S})\), we simply say a kernel on \((\mathsf S, \mathscr{S})\) or, even more simply, on \(\mathsf S\). Instead of saying a stochastic kernel from \((\mathsf S, \mathscr{S})\) to \((\mathsf T, \mathscr{T}),\) some books and papers say a stochastic kernel on \((\mathsf T, \mathscr{T})\) given \((\mathsf S, \mathscr{S}).\) We can view the stochastic kernel \(\kappa\) as a measurable function from \(\mathsf S\) to the space \(\mathcal{P}(\mathsf T)\) of probability measures on \((\mathsf T, \mathscr{T})\), where the \(\sigma-\)algebra on \(\mathcal{P}(\mathsf T)\) is generated by the weak topology, as mentioned above. For this reason, stochastic kernel are also called random probability measures. We can also view the stochastic kernel \(\kappa\) as a probabilistic generalization of the concept of function from \(\mathsf S\) to \(\mathsf T\)–instead of associating with each \(x \in \mathsf S\) a unique value from \(\mathsf T\), we associate a probability distribution on \(\mathsf T.\)
The term kernel, without the adjective stochastic, will be used to denote a similar object as a stochastic kernel except that the property 2 in the definition above states \(B \mapsto \kappa(x,B)\) is a measure on \((\mathsf T, \mathscr{T})\) for each \(x \in \mathsf S.\)
Examples
Given a measurable space \((\mathsf S, \mathscr{S})\), the function
\[\begin{aligned} \mathsf S \times \mathscr{S} \ni (x,B) \mapsto \kappa(x,B) = \begin{cases} 1 &\text{if } x \in B, \\ 0 &\text{if } x \in \mathsf S \setminus B \end{cases}\end{aligned}\]defines a stochastic kernel on \((\mathsf S, \mathscr{S})\), called the unit kernel. For each \(x \in \mathsf S\), the measure \(B \mapsto \kappa(x,B)\) is the Dirac measure \(\delta_x\) on \((\mathsf S, \mathscr{S})\) at \(x.\)Given two measurable spaces \((\mathsf S, \mathscr{S})\) and \((\mathsf T, \mathscr{T})\) and a measure \(\nu\) on \((\mathsf T, \mathscr{T})\), the function
\[\begin{aligned} \mathsf S \times \mathscr{T} \ni (x,B) \mapsto \kappa(x, B) := \nu(B)\end{aligned}\]defines a kernel from \((\mathsf S, \mathscr{S})\) to \((\mathsf T, \mathscr{T})\) which does not depend on \(x.\) Therefore, every measure can be seen as a special type of a kernel.Given two measurable spaces \((\mathsf S, \mathscr{S})\) and \((\mathsf T, \mathscr{T})\) and a measurable function \(f \colon \mathsf{S} \to \mathsf T\), the function
\[\begin{aligned} \mathsf S \times \mathscr T \ni (x,B) \mapsto \kappa(x,B) := \mathbf{1}_B(f(x))\end{aligned}\]defines a stochastic kernel from \((\mathsf S, \mathscr{S})\) to \((\mathsf T, \mathscr{T}).\)Consider the two measurable spaces \((\mathsf S = \{1, 2, \ldots, n\}, \mathfrak{P}(\mathsf S))\) and \((\mathsf T = \{1, 2, \ldots, m\}, \mathfrak{P}(\mathsf T))\) for two positive integers \(n\) and \(m\), with \(\mathfrak{P}(\mathsf X)\) denoting the power set of a set \(\mathsf X.\) Suppose we are given an \(n \times m\) matrix \(\mathbf K\) containing non-negative elements such that the sum along each row is \(1.\) Then the function \(\kappa\) defined by
\[\begin{aligned} \mathsf S \times \mathfrak{P}(\mathsf T) \ni (i,B) \mapsto \kappa(i, B) := \sum_{j \in B} \mathbf K_{i,j}\end{aligned}\]is a stochastic kernel from \(\mathsf S\) to \(\mathsf T.\) The case where \(\mathsf S\) or \(\mathsf T\) are countably infinite is similar.
Regular Conditional Distribution
In most discussions of MDPs the notion of conditional distribution and the associated notation are left frustratingly ambiguous. To remedy this let us spend some time discussing regular conditional distribution and disintegration in this subsection and the next. I also discussed the idea of regular conditional distribution in a previous blog post.
Let us start with a well-known but important result.
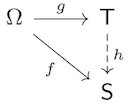
The sufficiency is very easy to verify. Indeed, if \(f = h \circ g\) for some measurable function \(h \colon \mathsf T \to \mathsf S,\) then for any \(S \in \mathscr S\) we have \(f^{-1}(S) = g^{-1}(h^{-1}(S)) \in \sigma(g).\)
For the necessity, we first prove the lemma for the case \(\mathsf S = [0,1].\) Then using Propositions 2 and 3 we will extend the argument to an arbitrary standard Borel space. This is the typical way to deal with standard Borel spaces.
So suppose that \(\mathsf S = [0,1].\) If \(f = \mathbf{1}_A\) for \(A \in \sigma(g),\) then by the definition of \(\sigma(g)\) there exists a set \(B \in \mathscr{T}\) such that \(A = g^{-1}(B).\) Then we can write \(f = \mathbf{1}_B \circ g,\) where \(\mathbf{1}_B \colon \mathsf T \to \mathsf S\) is of course measurable. Linearity allows us to deduce our desired conclusion for the case when \(f\) is a simple function. For a general \(\sigma(g)-\)measurable \(f,\) we know that we can find a sequence \(\{f_n\}\) of nonnegative simple \(\sigma(g)-\)measurable functions with \(f_n \uparrow f.\) Therefore, for each \(n\) we may choose measurable \(h_n \colon \mathsf T \to \mathsf S\) such that \(f_n = h_n \circ g.\) Then \(h := \sup_n h_n\) is again measurable, and we have
Finally, we extend the proof to the general case of \(\mathsf S\) being a standard Borel space. Propositions 2 and 3 imply that there exists an isomorphism \(\iota \colon \mathsf S \to [0,1].\) The preceding argument applied to the \(\sigma(g)-\)measurable function \(\iota \circ f \colon \Omega \to [0,1]\) implies that there exists a measurable function \(h_\iota \colon \mathsf T \to [0,1]\) such that \(\iota \circ f = h_\iota \circ g.\) But since \(\iota\) is a bijection, we can write \(f = (\iota^{-1} \circ h_\iota) \circ g.\) The function \(h := \iota^{-1} \circ h_\iota \colon \mathsf T \to \mathsf S\) is our desired measurable function.
Under the setting of the above lemma, suppose \(X \colon \Omega \to [0, \infty]\) is a random variable and \(Y \colon \Omega \to \mathsf T\) is a measurable function. Then the lemma above implies that the conditional expectation \(\mathbb{E}[X \mid Y]\) can be written as \(h \circ Y\) for some measurable \(h \colon \mathsf T \to [0, \infty].\)
Notation: We use \(\mathbb{E}[X \mid Y=y]\) to denote \(h(y).\)
Here the non-negativity of \(X\) is inessential, except for ensuring that the conditional expectation exists—we could have assumed \(X\) to be real-valued and integrable.
Before we discuss regular conditional distribution in full generality, let us discuss the simpler concept of regular conditional probability.
Regular Conditional Probability
Let \((\Omega, \mathscr{F}, \mathbb P)\) be a probability space and \(\mathscr G\) be a sub-\(\sigma\)-algebra of \(\mathscr F.\) For \(A \in \mathscr F,\) if we denote with \(\kappa(A)\) a version of the conditional probability \(\mathbb{P}(A \mid \mathscr G),\) and use \(\kappa_\omega(A)\) to denote \(\kappa(A)(\omega),\) then we have
\(\kappa(\varnothing) = 0\) a.s.;
\(\kappa(\Omega) = 1\) a.s.;
the mapping \(\omega \mapsto \kappa_\omega(A)\) is \(\mathscr G-\)measurable for each \(A \in \mathscr F\); and
by the monotone convergence theorem for conditional expectations, for every disjointed sequence \(\{A_n\}\) in \(\mathscr F,\)
\[\begin{aligned} \kappa_\omega\left( \bigcup_n A_n \right) = \sum_n \kappa_\omega(A_n)\end{aligned}\]for every \(\omega\) outside a null set.
With these properties the function \((\omega, A) \mapsto \kappa_\omega(A)\) looks very much like a stochastic kernel. But the fact that the null set in property 4 depends on the sequence \(\{A_n\}\) and that there could be uncountably many such sequences, means that \(\kappa\) is, in general, not a stochastic kernel. When \(\kappa\) can be made into a stochastic kernel we get a very special object called a regular version of the conditional probability, or simply regular conditional probability.
Recall Theorem 2 from a previous blog post which I state here again:
When does a regular conditional probability exist? Intuitively, we need to impose conditions on either the sub-\(\sigma\)-algebra \(\mathscr G\) or on the probability space \((\Omega, \mathscr{F}, \mathbb P).\) In the first case, suppose \(\mathscr G\) is generated by a countable partition \(\{A_n\}\) of \(\Omega,\) which is the case when \(\mathscr G\) is generated by a random variable taking values in a countable space. Then define
For the case where \(\mathscr{G}\) could be arbitrary, we have the following result.
The proof of this theorem will be a simple consequence of the existence of regular conditional distributions which we discuss next.
Regular Conditional Distribution
(From (Cinlar, 2011) Theorem IV.2.10) As in the proof of Lemma 1, we first give the proof for a special case of \(\mathsf S\), which here we assume \(\mathsf S = \overline{\mathbb R} := [-\infty, +\infty]\) and \(\mathscr S\) being its Borel \(\sigma-\)algebra. For each \(q \in \mathbb{Q},\) define
We shall construct the regular conditional distribution \(\kappa\) of \(X\) given \(\mathscr G\) from these countably many random variables \(\{C_q\}_{q \in \mathbb Q}.\) For \(q < r,\) we have \(\{X \le q \} \subseteq \{X \le r\},\) and therefore by the monotonicity of conditional expectations the event
The resulting extension \(\mathbb{R} \ni t \mapsto C_t(\omega_0) \in [0,1]\) is non-decreasing, right-continuous, and satisfies \(\lim_{t \to -\infty} C_t(\omega_0) = 0\) and \(\lim_{t \to \infty} C_t(\omega_0) = 1,\) and therefore is a probability distribution function. Denote with \(\overline{\kappa}_{\omega_0}\) the probability measure on \(\mathscr S\) associated with this probability distribution function. Now define
We claim that \(\kappa\) is a regular conditional distribution of \(X\) given \(\mathscr G.\) Let us verify the required properties one by one—the first two being the two properties in Definition 4 and the last being (1).
We will use Dynkin’s theorem (Theorem 4 here), which is a type of monotone class argument. Consider the collection
\[\begin{aligned} \mathscr D = \left\{B \in \mathscr S \; : \; \omega \mapsto \kappa_\omega(B) \text{ is } \mathscr G\text{-measurable}\right\}.\end{aligned}\]\(\kappa_\omega(\mathsf S) = 1\) for all \(\omega \in \Omega\) and therefore \(\omega \mapsto \kappa_\omega(\mathsf S)\) is \(\mathscr G-\)measurable, showing \(\mathsf S \in \mathscr D.\) For \(A \subseteq B\) with \(A, B \in \mathscr S,\) we have \(\kappa_\omega(B \setminus A) = \kappa_\omega(B) - \kappa_\omega(A),\) and therefore if \(A\) and \(B\) are in \(\mathscr D\) with \(A \subseteq B\) then so does \(B \setminus A.\) Finally, if \(B_1 \subseteq B_2 \subseteq \cdots\) is an increasing sequence in \(\mathscr D,\) then using the continuity of measure from below and the fact that the pointwise limit of measurable functions is again measurable, we get that \(\bigcup_n B_n \in \mathscr D.\) We conclude that \(\mathscr D\) is a d-system.
By the Dynkin’s theorem, to show that \(\mathscr D = \mathscr S,\) it is enough to show that \(\mathscr D\) contains the \(\pi\)-system \(\left\{ \lbrack - \infty, t \rbrack \,:\, t \in \overline{\mathbb R}\right\}.\) For \(t = +\infty\) we have already shown that \([-\infty, t] \in \mathscr D.\) Similarly it is easy to see that for \(t = -\infty\) we have \([-\infty, t] = \varnothing \in \mathscr D.\) Fix a \(t \in \mathbb R\) and note that we can write
\[\begin{aligned} \kappa_\omega([-\infty, t]) &= \mathbf{1}_{\Omega_0}(\omega) \; C_t(\omega) + \mathbf{1}_{\Omega \setminus \Omega_0}(\omega) \; \delta_0([-\infty, t]) = \lim_{\stackrel{q \in \mathbb Q}{q > t}} \mathbf{1}_{\Omega_0}(\omega) \; C_q(\omega) + \mathbf{1}_{\Omega \setminus \Omega_0}(\omega) \; \delta_0([-\infty, t]). \end{aligned}\]Since each of \(\left\{ C_q,\, q \in \mathbb Q\right\}, \mathbf{1}_{\Omega_0}\) and \(\mathbf{1}_{\Omega \setminus \Omega_0}\) is \(\mathscr G-\)measurable, and \(\delta_0([-\infty, t])\) is a constant, the map \(\omega \mapsto \kappa_\omega([-\infty, t])\) is \(\mathscr G-\)measurable.
We conclude that \(\omega \mapsto \kappa_\omega(B)\) is \(\mathscr G-\)measurable for each \(B \in \mathscr S.\)
For each \(\omega \in \Omega,\) \(B \mapsto \kappa_\omega(B)\) is clearly a probability measure on \(\mathscr S.\)
To verify (1), we need to show that \[\begin{aligned} \int_G \kappa(B) \, \mathrm{d}\mathbb{P} = \mathbb{P}(G \cap \{X \in B\}), \quad G \in \mathscr{G}, B \in \mathscr S.\end{aligned}\] By the same Dynkin’s theorem-type argument as in 1. above, we need to show (2) for \(B = [-\infty, t]\) with \(t \in \mathbb R.\) By the definition of \(C_q\) we get
\[\begin{aligned} \mathbb{P}(G \cap \{X \in B\}) = \mathbb{P}(G \cap \{X \le t\}) = \lim_{\stackrel{q \in \mathbb Q}{q > t}} \mathbb{P}(G \cap \{X \le q\}) = \lim_{\stackrel{q \in \mathbb Q}{q > t}} \int_G C_q \, \mathrm{d}\mathbb{P}.\end{aligned}\]Now note that for \(\omega \in \Omega_0,\) \(C_q(\omega) \to C_t(\omega) = \kappa_\omega(B)\) as \(q \downarrow t.\) Therefore using monotone convergence theorem and the fact that \(\Omega_0\) is of full measure, we can write\[\begin{aligned} \lim_{\stackrel{q \in \mathbb Q}{q > t}} \int_G C_q \, \mathrm{d}\mathbb{P} = \lim_{\stackrel{q \in \mathbb Q}{q > t}} \int_{G \cap \Omega_0} C_q \, \mathrm{d}\mathbb{P} = \int_G \kappa(B) \, \mathrm{d}\mathbb{P}.\end{aligned}\]This implies (2).
This completes the proof for the special case when \(\mathsf S = \overline{\mathbb R}.\) To extend the proof to arbitrary standard Borel spaces, suppose \(\iota \colon \mathsf S \to [0,1]\) is an isomorphism. The preceding argument applied to the real-valued random variable \(\iota \circ X\) shows the existence of the regular conditional distribution \(\kappa^\iota\) of \(\iota \circ X\) given \(\mathscr G.\) Now define
Regular conditional probabilities and regular conditional distributions are closely related. If \(\kappa\) is a regular version of the conditional probability \(\mathbb{P}(\cdot \mid \mathscr G),\) then \(\kappa^X\) defined as
Suppose in the setting of Definition 6, we also have a measurable space \((\mathsf T, \mathscr T)\) and a random element \(Y \colon \Omega \to \mathsf T.\) Then by the conditional distribution of \(X\) given \(Y\) we will mean the conditional distribution of \(X\) given \(\sigma(Y).\)
Disintegration
Let us first recall the construction of measures on a product space, which is closely tied with disintegrations. Suppose \((\mathsf S, \mathscr{S})\) and \((\mathsf T, \mathscr{T})\) are measurable spaces, \(\mu\) is a measure on \((\mathsf S, \mathscr{S})\), and \(\kappa\) is a kernel from \((\mathsf S, \mathscr{S})\) to \((\mathsf T, \mathscr{T})\) that can be written as \(\kappa = \sum_{n=1}^\infty \kappa_n\) for kernels \(\kappa_n\) from \((\mathsf S, \mathscr{S})\) to \((\mathsf T, \mathscr{T})\) that satisfy \(\kappa_n(x, \mathsf{T}) < \infty\) for each \(x \in \mathsf{S}\) (such kernels \(\kappa\) are called \(\Sigma-\)finite). If \(f \colon \mathsf{S} \times \mathsf{T} \to [-\infty, +\infty]\) is measurable, recall that \(x \mapsto f(x,y)\) is measurable for each \(y \in \mathsf T\) and \(y \mapsto f(x,y)\) is measurable for each \(x \in \mathsf S.\) If \(f \in (\mathscr S \otimes \mathscr T)_+\), then
Disintegration asks the converse to the construction of measures on product spaces: Given a measure \(\gamma\) on the product space \((\mathsf{S} \times \mathsf T, \mathscr S \otimes \mathscr T)\) does there exist a measure \(\mu\) on \((\mathsf S, \mathscr{S})\) and a kernel \(\kappa\) from \((\mathsf S, \mathscr{S})\) to \((\mathsf T, \mathscr{T})\) such that (3) holds? We will answer this in the affirmative for the special case for probability measures and stochastic kernels. For a more thorough discussion see the paper (Chang and Pollard, 1997).
(From (Cinlar, 2011) Theorem IV.2.18)
We will use Theorem 2 by converting the theorem above to its special case. Define the probability space \((\Omega, \mathscr F, \mathbb P) = (\mathsf{S} \times \mathsf T, \mathscr S \otimes \mathscr T, \gamma).\) Define the random elements \(Y \colon \Omega \to \mathsf S\) and \(X \colon \Omega \to \mathsf T\) as the projections \((s,t) \mapsto s\) and \((s,t) \mapsto t\) respectively. Let \(\mu\) be the distribution of \(Y\), i.e., \(\mu(A) = \gamma(A \times \mathsf T)\) for every \(A \in \mathscr S.\) Applying Theorem 2 to \(\mathscr G = \sigma(Y)\) shows that there exists a version of the regular conditional distribution of \(X\) given \(\mathscr G,\) which we will denote by \(\overline\kappa.\) Recall that \(\overline\kappa\) is a stochastic kernel from \((\Omega, \mathscr G)\) to \((\mathsf T, \mathscr T)\) such that
\[\begin{aligned} \mathbb{E}\left[ g\,\overline\kappa(B)\right] = \mathbb{E}\left[\mathbf{1}_{\{X \in B\}} g\right], \quad B \in \mathscr T, \, g \in \mathscr G_+.\end{aligned}\]By the structure of \(Y\), we see that \(\mathscr G\) consists of measurable rectangles of the form \(A \times \mathsf T\) for \(A \in \mathscr S.\) Therefore, the Doob-Dynkin factorization lemma implies that a function \(g \colon \Omega \to [0, \infty]\) is \(\mathscr G-\)measurable if and only if \(g((s,t)) = \overline{g}(s)\) for some measurable \(\overline{g} \colon \mathsf S \to [0, \infty].\) Now using equation (4), we conclude that \(\overline \kappa((s,t), B) = \kappa(s, B)\) for some stochastic kernel \(\kappa\) from \((\mathsf S, \mathscr S)\) to \((\mathsf T, \mathscr T).\)
If \(A \in \mathscr S\) and \(B \in \mathscr T\), equation (4) allows to write
Now a natural question is if \(\mu\) is a probability measure, corresponding to the law of a random variable \(Y \colon \Omega \to \mathsf S,\) and \(\kappa\) is a stochastic kernel, such that the product measure \(\mu \otimes \kappa\) corresponds to the law of a random vector \((Y, X) \colon \Omega \to \mathsf{S} \times \mathsf T,\) with \(X \colon \Omega \to \mathsf T\) being some random variable, can we associate \(\kappa\) with the conditional distribution for \(X\) given \(Y?\) The next theorem answers this question.
The proof for the statement about \(\eta\) follows the same line of reasoning as the proof of Theorem 3.
To see (5), note that for \(h \in \mathscr T_+\) and \(g \in \mathscr S,\) property (3) for \(\mu \otimes \kappa\) implies that
Since every function in \(\mathscr G_+\) is of the form \(g(Y),\) we get
Now if \(f \in (\mathscr S \otimes \mathscr T)_+\) is such that it is the product \(f = g \cdot h,\) then since \(g(Y)\) is \(\mathscr G-\)measurable, we get
Finally, a monotone class argument finishes the proof.
Although we won’t be needing it, let me briefly mention the notion of generalized disintegration.
Definition 7 (General disintegration): Let \((\mathsf E, \mathscr E)\) and \((\mathsf S, \mathscr{S})\) be measurable spaces, \(\psi \colon \mathsf E \to \mathsf S\) be a measurable mapping, \(\gamma\) be a measure on \((\mathsf E, \mathscr E),\) and \(\mu\) be a measure on \((\mathsf S, \mathscr S).\) We call a kernel \(\kappa\) from \((\mathsf S, \mathscr{S})\) to \((\mathsf E, \mathscr{E})\) a \((\psi, \mu)-\)disintegration of \(\gamma\) if
\(\kappa_x\{\psi \neq x\} = 0\) for \(\mu-\)a.e. \(x\), and
we have the following iterated integral for each \(f \in \mathscr E_+,\)
Note that, because of property 1, we can write (6) as
The disintegration discussed in Theorem 3 is a special case of the disintegration discussed in Definition 7. To see this, let \((\mathsf E, \mathscr E)\) be the product space \((\mathsf{S} \times \mathsf T, \mathscr S \otimes \mathscr T)\) and \(\psi \colon \mathsf S \times \mathsf T \to \mathsf S\) be the canonical projection. \(\{\psi = x\}\) is then simply \(\mathsf T\) and equation (6) becomes equation (3).
The following existence theorem is taken from Pollard’s book (Pollard, 2010).
Theorem 5: Under the setting of Definition 7, assume that
\((\mathsf E, \mathscr E)\) is a metric space endowed with its Borel \(\sigma-\)algebra,
\(\gamma\) and \(\mu\) are \(\sigma-\)finite with \(\gamma\) being a Radon measure (i.e., \(\gamma(K) < \infty\) for each compact \(K\) and \(\gamma(B) = \sup_{K \subseteq B} \gamma(K),\) the supremum being taken over compact sets, for each \(B \in\mathscr E\)),
the image measure \(\gamma \circ \psi^{-1}\) of \(\gamma\) under \(\psi\) is absolutely continuous with respect to \(\mu,\) and
the graph \(\llbracket \psi \rrbracket := \{(y,x) \in (\mathsf E, \mathsf S) : \psi(y) = x\}\) is contained in the product \(\sigma-\)algebra \(\mathscr E \otimes \mathscr S.\)
Then \(\gamma\) has a \((\psi, \mu)-\)disintegration \(\kappa\), unique up to a \(\mu-\)equivalence, in the sense that if \(\overline \kappa\) is another \((\psi, \mu)-\)disintegration, then \(\mu\{x \in \mathsf S : \kappa_x \neq \overline\kappa_x\} = 0.\)
As an example of a Radon measure, every \(\sigma-\)finite measure on the Borel \(\sigma-\)algebra of a Polish space which assigns finite measure to compact sets is Radon.
As a curiosity check out lifting theory.
MARKOV DECISION PROCESS
Markov Decision Model
Let us start by defining the moving parts of a Markov decision process. Our model evolves through time such that we can observe the state of the model and take admissible actions at discrete times \(n = 0, 1, 2, \ldots.\) We will say \(n \ge 0\) to mean \(n\) is a non-negative integer.
State Space
We denote by \(\mathsf{S}_n\) the state space of the model at time \(n \ge 0.\) We will assume that for each \(n \ge 0\), \(\mathsf{S}_n\) is a standard Borel space endowed with its Borel \(\sigma-\)algebra.
Action Space
We denote by \(\mathsf A_n\) the action space at time \(n \ge 0.\) This is the set from which possible actions can be chosen at time \(n.\) It is possible that the admissible actions at time \(n\) is a strict subset of \(\mathsf A_n\) depending on the state of the model. We will again assume that for each \(n \ge 0\), \(\mathsf A_n\) is a standard Borel space endowed with its Borel \(\sigma-\)algebra.
Admissible Actions
For each \(n \ge 0\), we have a mapping
denotes the graphs of \(\alpha_n\) and \(f_n\) respectively. For a justification of these assumptions, see the section “A Note About Admissible Actions” below.
Transition Law
For each time \(n \ge 0\), we have a stochastic kernel
Reward Function
For each time \(n \ge 0\), we have a measurable reward function
Stationary Markov Decision Model
The sequence
Define the tuple \((\mathsf S, \mathsf A, \alpha, \kappa, r)\) as follows:
We will thus assume a stationary Markov decision model from now on.
Definition 8: A Markov decision model is a tuple
the state space \(\mathsf S\) which is a standard Borel space;
the action space or the control space \(\mathsf A\) which is a standard Borel space;
the mapping \(\alpha \colon \mathsf S \to \mathscr A\) from the state space to the measurable subsets of the action space, which assigns to each \(x \in \mathsf S\) the set \(\alpha(x)\) of admissible actions satisfying the assumptions: \[\begin{aligned} \llbracket\alpha\rrbracket \in \mathscr S \otimes \mathscr A,\end{aligned}\] \[\begin{aligned} \text{there exists a measurable } f \colon \mathsf S \to \mathsf A \text{ such that } \llbracket f \rrbracket \subseteq \llbracket \alpha \rrbracket;\end{aligned}\]
the stochastic kernel \(\kappa\) from the graph \(\llbracket \alpha \rrbracket\) of \(\alpha\) to \(\mathsf S\) called the transition law; and
the measurable reward function \(r \colon \llbracket \alpha \rrbracket \to [-\infty, \infty).\)
A Note About Admissible Actions
The raison d'être for the assumptions (7) and (8) is to avoid measurability hell. This is the topic of measurable selection theorems. I discussed these theorems under special cases in two previous blog posts for their applications to general theory of processes (they are called section theorems there which means the same thing as selection theorems).
Let us very briefly discuss measurable selection in a general setting. Let \((\mathsf T, \mathscr T)\) be a measurable space, \(\mathsf X\) be a topological space, and \(\phi \colon \mathsf T \to \mathfrak{P}(\mathsf X)\) be a set-valued function (also called a multifunction or a correspondence) taking values in the class of all subsets of \(\mathsf X.\) We say that a multifunction \(\phi\) is closed if \(\phi(t)\) is closed for each \(t \in \mathsf T.\) Note that \(\phi\) can be equivalently identified with a subset of \(\mathsf T \times \mathsf X.\) A selection (also called a section) of \(\phi\) is a function \(f \colon \mathsf T \to \mathsf X\) such that \(f(t) \in \phi(t)\) for each \(t \in \mathsf T.\) If \(\phi(t) \neq \varnothing\) for each \(t \in \mathsf T\), then at least one selection exists by the axiom of choice. Note that writing \(\llbracket f \rrbracket \subseteq \llbracket \phi \rrbracket\) is same as saying \(f\) is a selection of \(\phi.\) If we denote
To be able to study measurability of selections it seems natural to first define measurability of multifunctions, and then relate the two notions. It turns out doing so isn’t straightforward. But before we get to measurability, we need a notion of inverse for multifunctions, of which there are two natural ones. The upper inverse \(\phi^{*}\) and the lower inverse \(\phi_*\) are defined by
Note that \(\phi^*(A) = \mathsf X \setminus \phi_*(\mathsf X \setminus A)\), and therefore we can equivalently use either of the two inverses to define measurability notions. We say that \(\phi\) is
weakly measurable, if \(\phi_*(G) \in \mathscr T\) for each open \(G \subseteq \mathsf X\);
measurable, if \(\phi_*(F) \in \mathscr T\) for each closed \(F \subseteq \mathsf X\);
Borel measurable, if \(\phi_*(B) \in \mathscr T\) for each Borel subset \(B \subseteq \mathsf X.\)
For the inverses we have that
but unlike functions, the inverses of multifunctions don’t behave well with complements, thereby necessitating three notions of measurability above.
The most well-known measurable selection theorem is the Kuratowski–Ryll-Nardzewski selection theorem, which states that a weakly measurable closed multifunction into a Polish space admits a measurable selection. It can be shown that a weakly measurable closed multifunction into a separable metrizable space has measurable graph (in the product \(\sigma-\)algebra), and conversely if a closed multifunction into a separable metrizable space is compact-valued such that its graph is measurable, then it is weakly measurable. The converse allows usage of Kuratowski–Ryll-Nardzewski selection theorem to justify existence of a measurable selection. This explains why many papers and books in control, instead of having the lazy assumption (8), assume that the mapping \(\alpha\) in definition 8 is compact-valued, an assumption which also has the advantage of being more explicit and avoiding inconsistencies.
Assumption (8) circumvents bringing conditions for measurable selection theorems in our discussion ahead, while assumption (7) allows us to define \(\kappa.\) For more details check the two review papers (Wagner, 1977), (Wagner, 1980) or Chapter 18 of the book (Aliprantis and Border, 2006).
Policy
A policy \(\pi = \{\pi_n\}_{n \ge 0}\), also known as an admissible control, is a sequence of prescriptions \(\pi_n\) that at time \(n\) gives a rule for selecting an action. \(\pi_n\) can be a randomized procedure or a deterministic procedure; it can depend on the entire history of the model or only on the current state. Let us formalize this concept.
History
An element \(h_n \in \mathsf H_n\) is of the form \(h_n = (x_0, a_0, x_1, a_1, \ldots, x_{n-1}, a_{n-1}, x_n).\)
Classes of Policies
The largest class of policies we consider is \(\Pi\) defined above. If instead of using the entire history, the policy makes a decision using only the current state, then we get a Markov policy.
We will sometimes abuse notation and write \(\pi = \{\varphi_n\}_{n \ge 0}\) for a Markov policy, where \(\varphi_n\) are the stochastic kernels as above. Even more simply, if our policy at each time doesn’t depend on the time but only on the current state, we get a stationary policy. A stationary policy is necessarily Markovian.
What about deterministic policies?
The set \(\Pi\) contains these deterministic policies, as can be easily seen by observing that for the deterministic policy \(\phi = \{f_n\}_{n \ge 0}\) the corresponding policy \(\pi = \{\pi_n\}_{n \ge 0}\) is given by
We thus have the following inclusions:
Canonical Construction
A natural question now arises to the suspicious reader about the existence of a probability space on which the random quantities discussed above are from. More precisely:
Given a Markov decision model \((\mathsf S, \mathsf A, \alpha, \kappa, r)\), a policy \(\pi \in \Pi,\) and a probability measure \(\nu\) on \(\mathsf S\), does there exist a probability space \((\Omega, \mathscr{F}, \mathbb{P}_{\nu}^{\pi}),\) and two stochastic processes \(\{X_n\}_{n \ge 0}\) and \(\{A_n\}_{n \ge 0}\) on this probability space, with the random variable \(X_n\) taking values in \(\mathsf S\) and the random variable \(A_n\) taking values in \(\mathsf A\) for each \(n \ge 0\), such that the following three properties hold true?
The law of \(X_0\) equals \(\nu\), i.e.,
\[\begin{aligned} \mathbb{P}_\nu^\pi\{X_0 \in B\} = \nu(B), \quad B \in \mathscr S.\end{aligned}\]If \(H_n = (X_0, A_0, \ldots, X_{n-1}, A_{n-1}, X_n) \colon \Omega \to \mathsf{H}_n\) denotes the history random variable, the joint distribution of \((H_n,A_n)\) is given by \((\mathbb{P}_\nu^\pi \circ H_n^{-1}) \otimes \pi_n.\) More intuitively, by Theorem 4, this means that the stochastic kernel \(\overline{\pi}_n\) from \((\Omega, \sigma(H_n))\) to \((\mathsf{A}, \mathscr A)\) defined by \[\begin{aligned} \overline\pi_n(\omega, C) = \pi_n(H_n(\omega), C), \quad \omega \in \Omega,\, C \in\mathscr A,\end{aligned}\] is a version of the conditional distribution of \(A_n\) given \(H_n.\)
The joint distribution of \((H_n, A_n, X_{n+1})\) is given by \((\mathbb{P}^\pi_\nu \circ (H_n, A_n)^{-1}) \otimes \kappa.\) More intuitively, by Theorem 4, this means that the stochastic kernel \(\overline\kappa_n\) from \((\Omega, \sigma(H_{n}, A_n))\) to \((\mathsf S, \mathscr S)\) defined by \[\begin{aligned} \overline\kappa_n(\omega, B) = \kappa((X_n(\omega), A_n(\omega)), B), \quad \omega \in \Omega,\, B \in \mathscr S,\end{aligned}\] is a version of the conditional distribution of \(X_{n+1}\) given \((H_n, A_n).\)
The answer to our question is, of course, yes. At this point recall the Ionescu-Tulcea theorem:
To this end, define
Then Theorem 5 implies that there exists a probability space \((\Omega, \mathscr{F}, \mathbb{P}_{\nu}^{\pi})\) satisfying (10), (11) and (12), where we define the random variables \(\{X_n\}_{n \ge 0}\) and \(\{A_n\}_{n \ge 0}\) by the projection maps:
We denote by \(\mathbb{E}_\nu^\pi\) the expectation operator with respect to the probability space \((\Omega, \mathscr{F}, \mathbb{P}_\nu^\pi).\) If \(\nu = \delta_x\) is a Dirac measure at \(x \in \mathsf S,\) we will simply write \(\mathbb{P}_x^\pi\) and \(\mathbb{E}_x^\pi\) for \(\mathbb{P}_{\delta_x}^\pi\) and \(\mathbb{E}_{\delta_x}^\pi.\)
Note that (1) implies that we can write (11) and (12) as \[\begin{aligned} \mathbb{P}_\nu^\pi\left[\{A_n \in C\} \mid \sigma(H_n)\right] = \pi_n(H_n, C), \quad C \in \mathscr A,\end{aligned}\] \[\begin{aligned} \mathbb{P}_\nu^\pi\left[\{X_{n+1} \in B\} \mid \sigma(H_n, A_n)\right] = \kappa((X_n, A_n), B), \quad B \in \mathscr S.\end{aligned}\]
Also notice that because of the constraint (9) on a policy, the probability measure \(\mathbb{P}_\nu^\pi\) is supported on the closure of the set of all possible histories \(\mathsf H_\infty := \mathsf S \times \llbracket \alpha \rrbracket^\infty.\)
Markov State Process
Although equation (14) looks like a Markov condition, the state process \(\{X_n\}\) may not be a Markov process because of the dependence on history through the action process. It seems intuitively plausible that if the policy is Markov, then the state process should also be Markov. We prove this now.
Notation: If \(\varphi\) is a stochastic kernel from \(\mathsf S\) to \(\mathsf A\), then for every \(x \in \mathsf S\), define
Note that \(r(\cdot, \varphi)\) is a measurable function and \(\kappa((\cdot, \varphi), \cdot)\) is a stochastic kernel on \(\mathsf S.\)
Let us start by fixing any policy \(\pi = \{\pi_n\}_{n \ge 0} \in \Pi\) and any \(B \in \mathscr S.\) Then
where the first equality follows from the tower rule for conditional expectation, the second equality follows from (14), and the third equality follows from (11) and (5).
Now if \(\pi = \{\varphi_n\}_{n \ge 0} \in \Pi_M\), then the equation above becomes \[\begin{aligned} \mathbb{P}_\nu^\pi\left[\{X_{n+1} \in B\} \mid \sigma(H_n)\right] =\int_{\mathsf A} \kappa((X_n, a), B) \,\varphi_n(X_n, \mathrm{d}a) = \kappa((X_n, \varphi_n), B).\end{aligned}\]
Then using the tower rule again, substituting equation (16), and using the fact that \(\kappa((X_n, \varphi_n), B)\) is \(\sigma(X_n)-\)measurable, the LHS of equation (15) can be written
OPTIMAL POLICIES
Until now we have implicitly assumed that the total period of time over which the system is observed is infinite. In many situations we are interested in the finite horizon problem. So let us denote by \(T \in \mathbb N \cup \{+\infty\}\) the length of this planning or control horizon. This gives a way to classify Markov decision processes—finite horizon or infinite horizon problems.
Markov decision processes can also be classified according to the performance criterion used.
Performance Criteria
Given a Markov decision model and an initial distribution, we have a choice over which policy to choose. We will need to define what performance criterion we are optimizing for to choose an optimal policy. Suppose we have a class \(\Pi_A\) of admissible policies, where \(\Pi_A\) could be \(\Pi\) or \(\Pi_{DM}\) or any other class we discussed above. The performance criterion measures how “good” a policy is. There are two performance criteria which are common in the literature: expected total reward and the long-run average expected reward per unit time.
Expected Total Reward
Recall that \(\mathbb{E}_x^\pi\) simply means \(\mathbb{E}_{\delta_x}^\pi.\) In this setting it is usually assumed that the reward function \(r\) is bounded, so that \(J(\pi, x)\) is a bounded function.
We use \(J^*\) to denote the value function
The problem is to find (if it exists!) a policy \(\pi^* \in \Pi_A\) such that
Long-run Average Expected Reward
We could have taken \(\limsup\), and both give different results, but the \(\liminf\) case is easier to handle. Intuitively, the \(\liminf\) case gives a more pessimistic picture, while the \(\limsup\) gives a more optimistic picture. See the survey (ABFGM, 1993) for a detailed treatment of this performance criterion. We will be focusing on the expected total reward next.
The choice of the performance criterion is application dependent. For example, if the future rewards are to be valued less than immediate rewards, then using expected total reward with \(\beta < 1\) would make sense. On the other hand, if the long term behaviour is to be studied and initial transient period is to be ignored, then using the long-run average expected reward makes sense.
Deterministic Markov Policy
Suppose that we are in the finite horizon with the expected total reward regime. Assume that the terminal reward is \(0\) for simplicity, and that the
As the notation suggests, we have also implicitly assumed that \(\alpha(x) = \mathsf A\) for every \(x \in \mathsf S.\) In this setting we want to compare the classes \(\Pi_D\) and \(\Pi_{DM}\) of policies. We claim that there is no loss of optimality in restricting attention to the smaller class \(\Pi_{DM}\) of deterministic Markov policies. This is a surprising result! Policies in \(\Pi_D\) can depend on the entire history in a very complicated manner, and it is not clear why a deterministic Markov policy should be just as good. I came across this result in a blog post by Maxim Raginsky (Raginsky, 2010). The key result which we will use is from a 1964 paper by David Blackwell (Blackwell, 1964). We state this result without proof.
Let us now state and prove our theorem. Instead of fixing an initial state \(x\) as above in the total expected reward function, we let the initial distribution be any probability measure \(\nu\) on \(\mathscr S.\)
Here, \(J(\pi)\), of course, denotes
Before we prove the theorem, let us establish two lemmas. The first lemma states that the theorem holds true for \(N=2.\)
The next lemma states that when \(N=3\) and the last policy \(\pi_2\) is Markov, then we can choose even the second policy to be Markov. More precisely,
Finally, we come to the proof of Theorem 9.
(of Theorem 9) Let \(\pi \in \Pi_D.\) The cases \(N=1\) and \(N=2\) follow from the lemmas 2 and 3. For \(N \ge 3\) we analyze as follows:
View \(\pi\) as a two-step policy \(((\pi_0, \ldots, \pi_{N-2}), \pi_{N-1})\) in an alternative two-step MDP. Then by Lemma 2, we can assume that \(\pi_{N-1}\) is a Markov policy.
Now view \(\pi\) as a three-step policy \(((\pi_0, \ldots, \pi_{N-3}), \pi_{N-2}, \pi_{N-1})\). The policy in the third time-step \(\pi_{N-1}\) is Markov, and so we can apply Lemma 3 to conclude that \(\pi_{N-2}\) is also Markov.
We continue in a similar manner for smaller indices \(k = N-3, N-4, \ldots\) to get our result.
This can be generalized to the class of all, and not necessarily deterministic, policies. I have not verified the proof, but it can be found in (Derman and Strauch, 1966) or Section 3.8 of (Dynkin and Yushkevich, 1979).
Dynamic Programming
Suppose, again, that we are in the finite horizon with the expected total reward regime. When can we say that there exists an optimal policy which is a deterministic Markov policy? Making some assumptions with regard to measurable selections, we can find, using dynamic programming, the optimal policy and the value function.
The equation defining \(J_n\)’s in the theorem statement is known as the dynamic programming equation.
EPILOGUE
It would be remiss of me to not mention the encyclopaedic reference (Bertsekas and Shreve, 1978). I also really liked the book (Hernández-Lerma and Lasserre, 1996), which has the advantage of being short. Next, I would be interested in learning reinforcement learning, where MDPs play a foundational role.
REFERENCES
Cinlar, E. (2011). Probability and Stochastics, Graduate Texts in Mathematics 261, Springer.
Chang, J. T. and Pollard, D. (1997). Conditioning as disintegration. Statistica Neerlandica, Vol. 51, nr. 3, pp. 287-317.
Pollard, D. (2010). A User's Guide to Measure Theoretic Probability. Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press.
Wagner, D. H. (1977). Survey of Measurable Selection Theorems, SIAM Journal of Control and Optimization Vol. 15, No. 5, August 1977.
Wagner, D. H. (1980). Survey of Measurable Selection Theorems - An update. Measure Theory Oberwolfach 1979, pp. 176-219, Lecture Notes in Mathematics, volume 794, Springer.
Aliprantis, R. and Border K. C. (2006). Infinite Dimensional Analysis - A Hitchhiker’s Guide. Third Edition, Springer.
Arapostathis A. , Borkar V. S., Fernandez-Gaucherand E., Ghosh M. K. and Marcus S. I. (1993). Discrete-Time Controlled Markov Processes with Average Cost Criterion - A Survey. SIAM Journal of Control and Optimization Vol. 31, No. 2, pp. 282-344, March 1993.
Raginsky, M. (2010). Blog post - Deadly ninja weapons: Blackwell’s principle of irrelevant information.
Blackwell, D. (1964). Memoryless Strategies in Finite-Stage Dynamic Programming. Ann. Math. Statist. 35(2): 863-865 (June, 1964).
Derman, C. and Strauch, R. E. (1966). A note on memoryless rules for controlling sequential control processes, Ann. Math. Statist. 37(1): 276-278 (February, 1966).
Dynkin, E. B. and Yushkevich, A. A. (1979). Controlled Markov Processes, Springer-Verlag, New York.
Bertsekas, D. P. and Shreve, S. E. (1978). Stochastic Optimal Control: The Discrete-Time Case, Academic Press.
Hernández-Lerma, O and Lasserre, J. B. (1996). Discrete-Time Markov Control Processes - Basic Optimality Criteria, Springer.